

NEWS & EVENTS
Insights on the Latest Trends and Evolving Market Dynamics
In recent years, with the rapid development of AI, a range of new terms such as DPU, NPU, TPU, and IPU—collectively known as “XPU”—have emerged. Are these truly distinct architectures, or just marketing terms from tech companies? In reality, from the perspective of CPU development, these XPUs are not traditional processors; rather, they are closer to specialized GPUs designed to handle specific workloads.
A CPU typically comprises logical units, control units, and registers. Equipped with complex digital and logical circuits and aided by mechanisms like branch prediction and out-of-order execution, the CPU excels in logical processing and computation, capable of handling complex, sequential tasks.
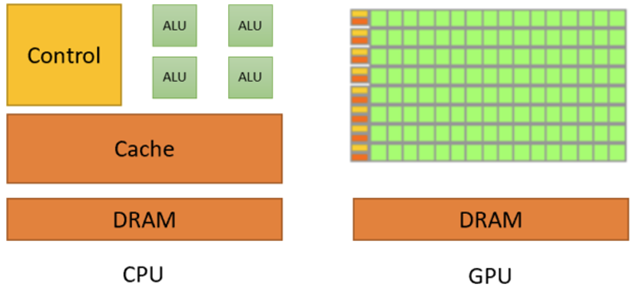
To minimize signal delays caused by frequent memory access, CPUs rely heavily on on-chip cache, reducing memory access latency to nearly zero. However, only a small portion of the CPU is dedicated to arithmetic logic units (ALUs), which can be a limitation in handling parallel computing. GPUs, in contrast, have simpler control logic and reduced cache, but they dedicate a large proportion of their chip area to ALUs, making them highly efficient in parallel processing tasks such as graphics rendering.
However, each GPGPU core has limited cache and simplified logical functions, supporting only basic operations. Cores within a GPGPU are typically grouped, and these groups must work cooperatively to complete tasks rather than operating independently.
GPGPU, or General-Purpose GPU, emerged as a solution to boost GPU efficiency. With the introduction of shaders (programmable components in 3D graphics rendering), GPUs gained programmability in the graphics pipeline, expanding their functionality beyond graphics processing and paving the way for GPGPU.

The GPGPU is a powerful computing tool that assists the CPU in non-graphical, complex calculations. In its design, the graphics display elements are removed, focusing entirely on general-purpose computing. This architecture became central to AI accelerator cards, enabling efficient data movement, processing, and handling of massive, high-concurrency workloads. Today, GPGPUs are used in fields like physics simulations, encryption, scientific calculations, and even cryptocurrency mining.
CUDA
As a chip architecture, NVIDIA’s leading GPGPU framework, CUDA, uses a parallel computing model that allows developers to program in C language and run tasks on NVIDIA GPUs. CUDA is easy to adopt with C-based syntax, an extensive library, and various tools to support high-performance computing. It also includes profiling tools like nvprof and Nsight, helping developers optimize code performance.
OpenCL
OpenCL (Open Computing Language) is an open standard maintained by the Khronos Group, supporting a wide range of computing devices, including CPUs, GPUs, and FPGAs. It provides cross-platform parallel programming capabilities and is compatible with hardware from multiple vendors like AMD, Intel, and NVIDIA. OpenCL offers a flexible programming interface with broad community support and documentation resources.
Vulkan
Another creation of the Khronos Group, Vulkan is a low-overhead, high-performance API for graphics rendering and computation. While primarily used for graphics, it also delivers powerful computational capabilities.
GPGPUs address the efficiency challenges CPUs face in concurrent processing. However, program management and organization come at a significant cost in silicon area and memory bandwidth, often leading to performance bottlenecks. To further enhance GPGPU efficiency, Google introduced the TPU (Tensor Processing Unit) in 2016, an ASIC designed specifically for tensor computations. In deep learning, tensors (multi-dimensional arrays) are essential, and TPUs enable efficient processing of tensor-based operations, representing a shift from general-purpose to specialized computing.

The NPU (Neural Processing Unit) is another specialized chip, tailored to AI tasks in IoT and mobile devices. NPUs accelerate neural network computations, addressing traditional processors’ limitations in handling such tasks. While Google’s TPU is primarily used in its cloud infrastructure, NPUs are commonly integrated into AI-focused devices like smartphones and IoT devices.
These architectures represent the evolving landscape of general-purpose to specialized computing in response to the growing demand for AI-driven workloads.
Related recommendations
Learn more news
Leading Provider of Server Solutions


YouTube

