

NEWS & EVENTS
Insights on the Latest Trends and Evolving Market Dynamics
Current location:
Home > News > Company News > An Overview of 8-GPU Server Interconnection TechnologiesToday, one of the most popular AI server models on the market is the 8-GPU server. In practical use, these machines leverage the power of multi-GPU parallel computing to handle massive inference tasks quickly, boosting deep learning model training and inference. With exceptional graphics processing capabilities, they also support real-time rendering for gaming applications. Thanks to these strengths in AI, inference, machine learning, and cloud gaming, 8-GPU servers have become a standout choice.
One of the first decisions when selecting an 8-GPU server is whether to choose a direct-connection model or an expanded-connection model. Generally, 8-GPU servers come equipped with powerful motherboards and additional PCIe lanes to support simultaneous high-speed data transfer. However, the limited PCIe lanes available from the CPU may restrict communication channels for some GPUs in actual usage.
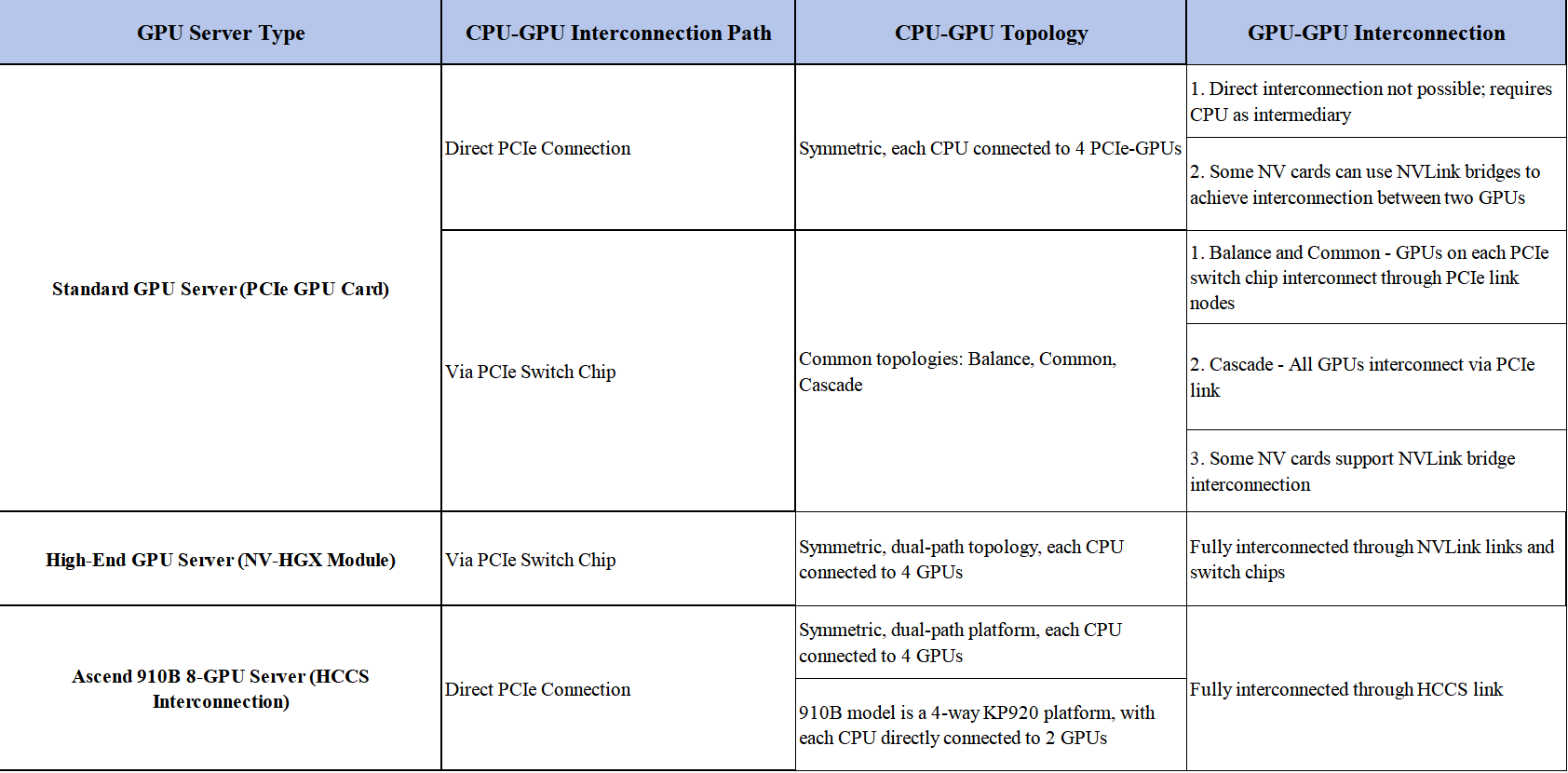
Gooxi AMD Milan platform’s 4U 8-GPU AI server, for example, uses direct connections. Internally, it is equipped with two AMD third-generation processors offering 128 PCIe lanes each, with three XGMI connections between CPUs, providing a total of 160 PCIe lanes. With 8 double-width GPUs occupying 128 PCIe lanes, 32 lanes remain available for other components, such as network or RAID cards.
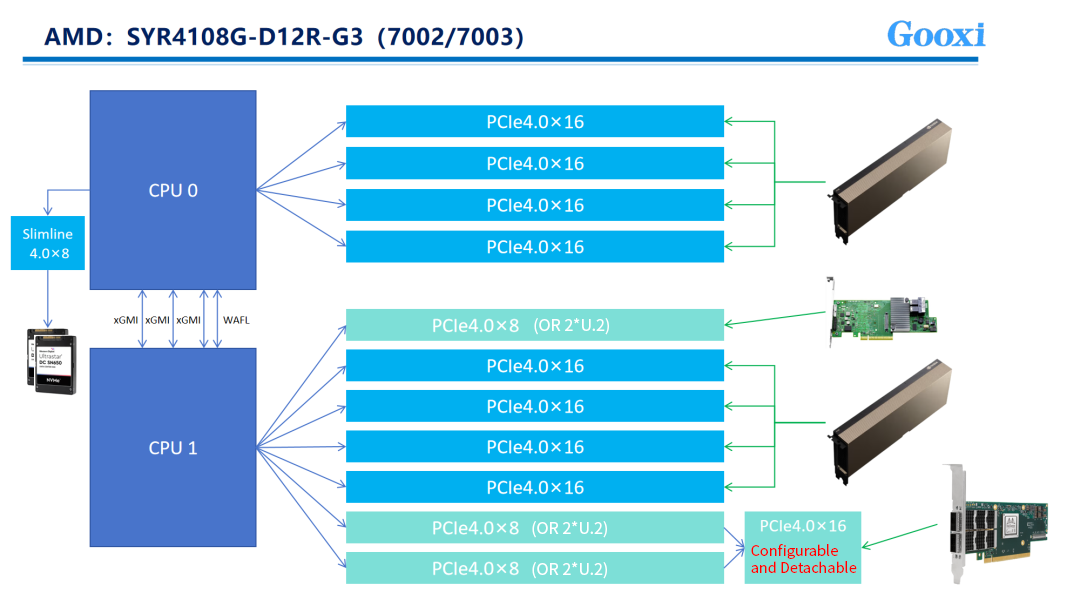
Gooxi Intel Whitley platform 4U 10-GPU AI server is an example of the expanded-connection model. It utilizes two third-generation Intel® Xeon® processors, each providing 64 lanes, for a total of 128 PCIe lanes. Eight double-width GPUs typically require all 128 lanes (16x8=128), and with 10 GPUs, up to 160 lanes may be needed. Consequently, the system employs two switch chips to expand the signal capacity, enhancing the server’s PCIe scalability. This enables multiple PCIe slots for additional network or RAID cards, meeting varied user needs across complex applications.
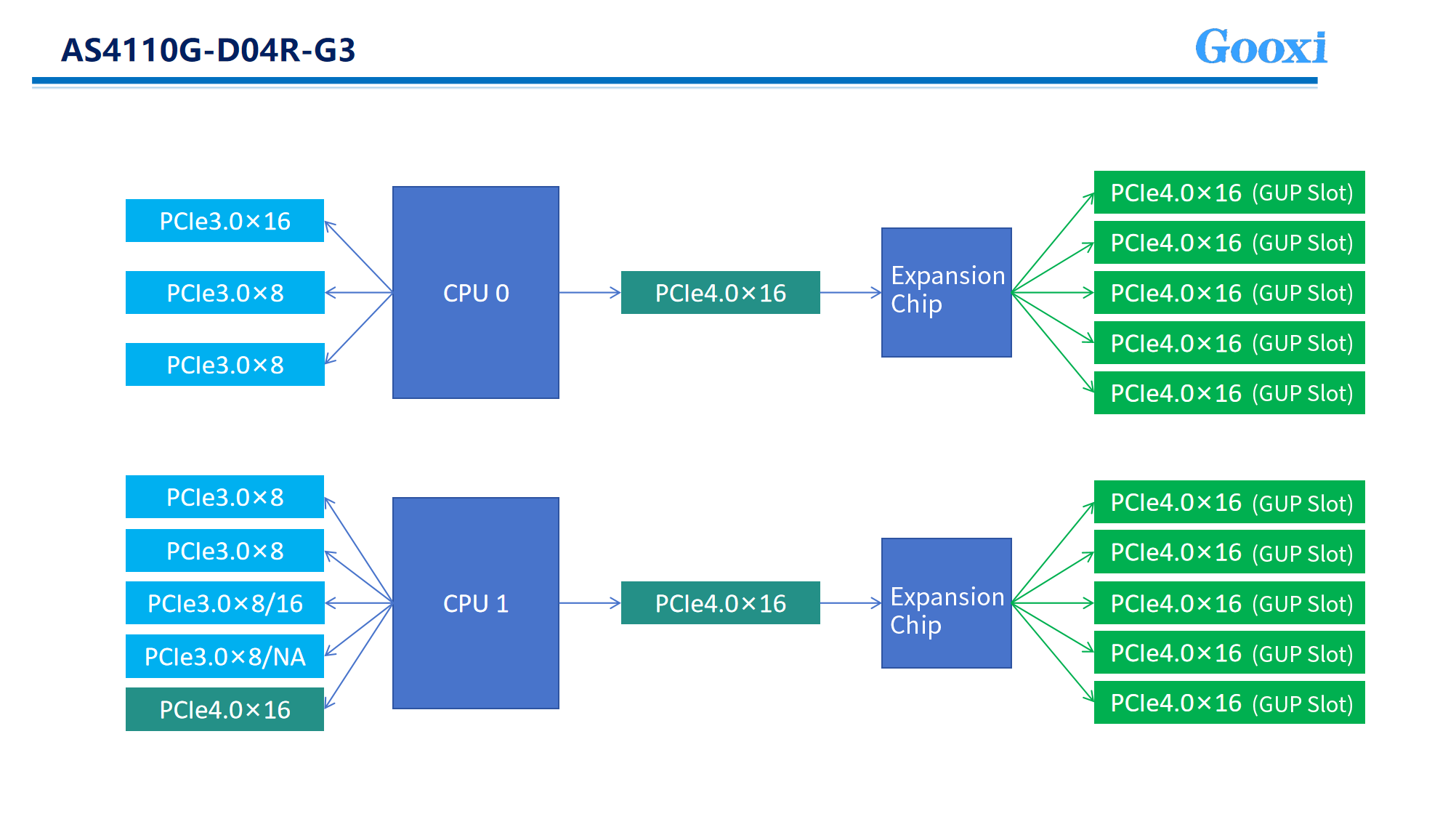
Switch connections offer different topology configurations: attaching the switch to one CPU, connecting switches to separate CPUs, or balancing the connections between the two. These options result in three topologies, commonly referred to as balance, common, and cascade.
Nvlink enables direct GPU-to-GPU interconnections, providing significantly higher bandwidth and lower latency than PCIe or CPU-CPU UPI connections, ideal for efficient inter-GPU communication.
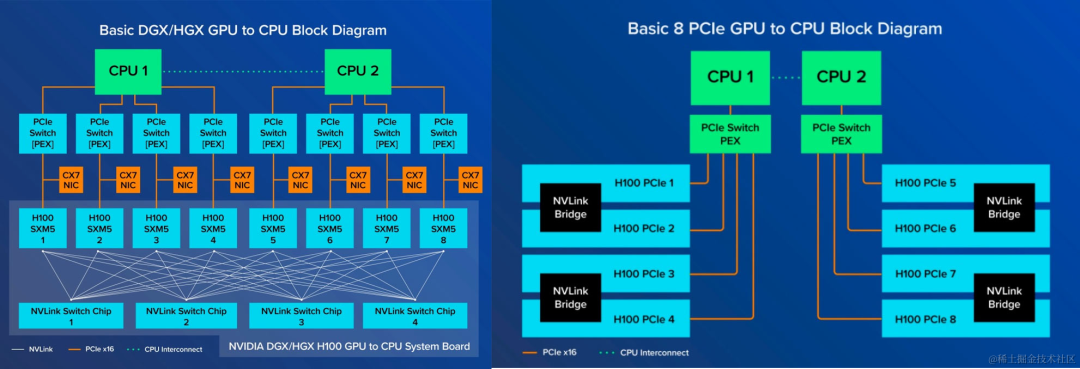
NVIDIA HGX is designed for large-scale computing with an array of eight SXM GPUs, interconnect backplanes, and NVLink switches, offering a high-bandwidth socket connection well-suited for NVIDIA DGX and HGX systems.
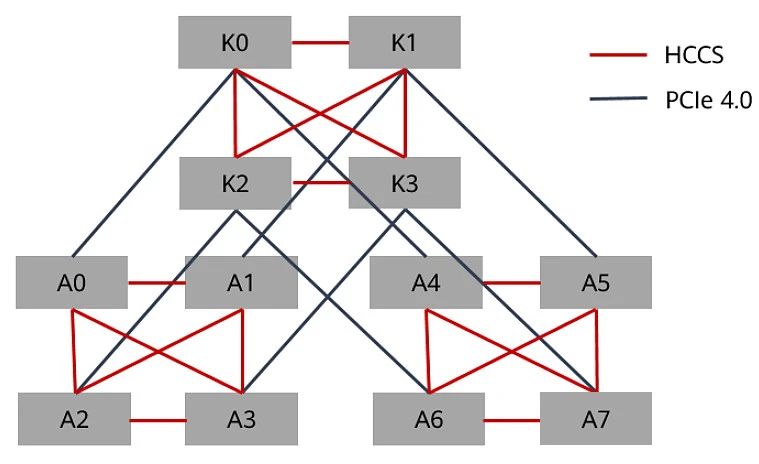
The Ascend 8-GPU model differs from general-purpose servers with its four-CPU design. In this configuration, each CPU supports PCIe 4.0x40, connecting to two NPUs, and uses the HCCS link for high-efficiency direct connections across nodes.
The 8-GPU direct connection model relies on CPU intermediation (CPU0→CPU1→GPU), which introduces some latency but offers a cost-effective solution for inference and cloud computing. The expanded-connection model, on the other hand, utilizes switch chips to boost signal transmission speed and PCIe scalability, making it ideal for scenarios where low-latency multi-GPU communication is essential, such as large-model training.
Among the numerous 8-GPU server options on the market, Gooxi AMD Milan platform 4U 8-GPU AI server strikes a balance between performance and cost. Its GPU communication efficiency can reach 17.22 GB/s, effectively enhancing large-model training speeds. Featuring third-generation AMD CPUs, it stands out for its high cost-effectiveness. (Feel free to contact us for pricing!)
Related recommendations
Learn more news
Leading Provider of Server Solutions


YouTube

